

There are many missteps in the app modernization journey. For more than ten years, we’ve worked with clients on hundreds of modernization projects, from single apps to portfolios of apps in large enterprises and our experience has led us to identify four of the most common anti-patterns impacting organizations. We’ve compiled the methodologies and techniques in the online e-book, The Legacy Trap, a resource to help you apply a business-driven methodology to escape the legacy trap
Before we dive into the four most common anti-patterns, let’s briefly look at what app modernization is and how it usually proceeds.
App modernization done well
Application modernization is the process of updating legacy software to take advantage of the benefits of modern computing platforms and infrastructure. This could involve any combination of the 5 R’s: Replatform, rehost, retain, retire, or rebuild/refactor, the latter of which is the focus for this article.
So, what’s a "legacy application?" Often, a legacy application is delivering value and supporting business processes, but it needs to be modernized for a few reasons: To take advantage of new platforms and infrastructure, to integrate with new services like biometric authentication, to use new features like generative AI, or even just for maintenance and upgrades. This is especially true when applications support multiple business domains, are the result of organizations merging, or they need to meet the needs of an evolving business.
Most of the legacy applications we encounter are "monolithic applications." A monolithic application is typically a single, tightly integrated software system that combines frontend, backend, and database into one architectural unit. It offers simplicity and release speed initially, but becomes cumbersome to maintain, modify, and scale due to its interconnected nature. When monoliths are holding back the business, it's time to modernize. Nowadays, in most cases, a microservices architecture is a common solution that typically involves the following steps:.
-
Microservices identification—Identify the new microservices by analyzing business processes and each legacy service and, most likely, breaking them up into several microservices.
-
Microservice architecture design—Define how these new microservices should interact with one another and define a common runtime and management model for the microservices.
-
Microservice implementation—This includes work, such as coding and ,that needs to be done to protect the new microservices from quickly aging into your new legacy services by prioritizing design decisions that make it easy to iterate on and maintain the new microservices.
-
Release to production—Do the work to ensure that new microservices can be incrementally delivered to work alongside an existing legacy system without disruption.
These steps are relatively straightforward if done in a systematic, disciplined way. However, it's easy to fall into some anti-patterns when modernizing apps.
Now, let's look at some of the anti-patterns we've encountered around these steps, and what we've learned to prevent them.
Microservice Identification Anti-Pattern: Relying only on code and documentation for business context
A common misstep when architecting legacy services to microservices is to make a functional, one to one replica of the legacy services. You simply look at what the existing services do, and you make sure the new bundle of microservices does that. The problem here is that your business has likely evolved its operations since the legacy services were made. That means that you likely don't need all the same functionality in the legacy services. And if you do need that functionality, you might need to do it differently, which is exactly the reason you are modernizing in the first place: The legacy services are no longer helping the business function as desired.
Often, organizations will consider modernizing as purely technical work and exclude business stakeholders from the process. This means developers won't have enough input from business stakeholders when picking which parts of the legacy services to replicate, which to drop, and which to improve. In this situation, developers will just replicate the legacy services.
When business stakeholders and users are not involved in microservice identification, you risk misalignment on new requirements and introducing new, potential problems or rework in the future. This misstep can be especially costly when dealing with complex systems.
Use event storming to avoid the microservices identification Anti-pattern
To avoid this anti-pattern, business and technical stakeholders should work collaboratively to conduct business domain discovery. Domain-driven design (DDD) is a software design that follows proven, practical principles and guidelines for business domain discovery. Doing DDD in-person with a whiteboard is an excellent and efficient way to create a shared understanding of business processes. This also makes it easier to do more than just replicate the existing legacy service in new microservices, and avoids the microservices identification anti-pattern. It’s also a great way to build relationships and trust with groups of people who usually don't know each other well.
Event storming is also a popular practice that we use at Tanzu Labs (formally Pivotal Labs) for this kind of work, and one we teach our customers to facilitate. We like event storming because it:
-
Creates a shared vocabulary between business and technical teams.
-
Gives technical teams the business context they need to design the new architecture.
-
Helps business stakeholders gain a better understanding of technical complexities.

We facilitated an Event Storming workshop to modernize a business-critical, customer-facing systema for a global shipping and logistics company based in Southeast Asia. The system had originally been intended to serve as a proof-of-concept, but proved itself so well that the organization operationalized it for thousands of customers, with business stakeholders passing a stream of new requirements to the development team over time. After two years of continued development, the application modules had become tightly coupled modules and there was minimal test coverage. The system faced mounting performance issues and it became increasingly difficult for the team to plan and implement new features or scale to more customers and use cases.
Our approach to solving these challenges included ithe involvement of six developers, two business owners, and one quality assurance tester. It took just five days to gain a clear and aligned understanding of 12 high-value business flows and the core business domains. From there we identified more than ten microservice candidates. The team was amazed at the efficiency of the process and the depth and clarity of knowledge transfer from the business owners.
This was the first time the technical team understood the business requirements for their software, and not just what the software should do, but why. This meant the developers could avoid the microservices identification anti-pattern, and avoid duplicating the legacy services in new code. This meant that only the services that were needed to meet the businesses’ requirements were implemented.
Microservice architecture design anti-pattern: Unvalidated architecture
When you know exactly what you want, traditional software development planning and enterprise architecture design can work. Knowing exactly what you want is rarely the case, though, when you're modernizing applications, and especially when you're converting them to microservices. As discussed in the microservice identification anti-pattern, the requirements for your legacy software have changed becuase your business needs it to do something different. Otherwise, you wouldn't be modernizing. In moments like this, you rarely know exactly what the software should do, so designing it up-front without experimenting and feedback is risky.
This introduces the second microservices modernization anti-pattern: Unvalidated architecture.
A validated architecture has actually been tested in production and shown to work. Instead of doing a complete, authoritative design, writing code, and then releasing it, you do very small loops of these cycles, testing your assumptions to validate, or invalidate, your theory of what works.
More than once, a customer in Singapore has asked ,“Can you help validate our new architecture design?” This is a symptom of unvalidated architecture. In this case, this means that a small group of architects (or just one) probably sat down and had a good think about what the ideal future-state architecture should be, based on their knowledge and, importantly, assumptions about the needs of business, engineering, and operations. Then drew up a beautiful grand plan that, in theory, should be fit for purpose. Of course, this is the traditional approach and is quite literally the job description and primary responsibility of a solution architect:
“A solution architect is a key role in the software development process, responsible for designing and planning the technical aspects of a software system” – Linkedin
Architects may have had many discussions with business and technical experts in order to gather requirements and test assumptions, and they may have even iterated on their design as they learned more. But, they often haven't actually put that design through the full testing of writing code, releasing the code, and seeing if it solves the understood requirements.
There's also a large risk of information loss when architects hand off the design outputs to developers without the business context and the reasoning. Design and requirements could be misunderstood or misinterpreted, and this loss of context often leads to odd coding decisions.
Furthermore, the plan is all theoretical until it can be built efficiently by engineers and validated through real working software in production. But, you reduce this risk when all the stakeholders work more closely, and more frequently, together. You also find a way to build and release something quickly in order to shorten the feedback loop. People often say they don't have time for this, or that it's unrealistic. But, we often ask, "As opposed to what works as effectively?"
Work together, instead of working apart, to avoid the unvalidated architecture anti-pattern
We've seen organizations avoid this anti-pattern when they encourage architects and engineers to work together to design the new enterprise architecture. This duo also brings in business stakeholders as needed to gain more context about the business domain. Bringing everyone into the architecture design workshop also builds trust and shared ownership because engineers are no longer implementing someone else’s design decisions with no input ord limited context. When developers contribute to the architecture and design, the architecture is as much their decision as the enterprise architects’. This means that developers are much more likely to uphold and do a good job implementing the architecture principles and governance over time.
To ensure focus on smaller batches of architecture/code/release, we also encourage starting with high-level, or “notional,” design. Notional design focuses only on the communication and data flows between services, so developers only make lower-level technical decisions as needed during implementation.
Notional architecture design should be done incrementally as design decisions are validated and needs are discovered to support business scenarios. To do this, begin by selecting one business process, which is one output of event storming. Then you only design an architecture that enables the functionality required for that process and you resist the urge to architect all the functionality that you think will eventually be needed for each service. Once this architecture is validated, you can move on to the next business process, and so on.
Once we cover high-priority, well-known business scenarios, we can move more quickly into implementation and delivery, and then test and validate (or invalidate) our assumptions with real world data and to, hopefully, faster deployment and feedback. Also, it's sometimes the case, that the business over-asked as well. Once you ship these early business processes, they may realize that the first -eight out 15 possible scenarios are good enough—sometimes more than good enough for the business. Developers aren't the only ones who gold plate.
Use boris to bring architects and developers together
One of the ways we bring architects and developers together is in a Boris workshop. A Boris workshop is a light-weight, collaborative activity that generates the notional architecture for microservices modernization by creating a planned set of services with well understood paths of synchronous or asynchronous data communication between them.
This then makes it easy to indicate the value of the functionality, define user stories for implementation, and highlight potential risks. It also enables developers to better understand and plan the implementation for something that can hopefully be released to users sooner, without going into too much detail. It’s easy to come back to this notional architecture to modify or expand on it later as needed, and all of this, together, helps you start converting your legacy services into microservices.
Let's look at an example: The architecture for a food delivery application. In this architecture, you'll discover many processes that were identified during business domain discovery, including searching, ordering, adding payment and logistical details, sending the order to the restaurant, assigning the driver, and more.
After listing out these processes, we may be able to identify some service candidates, as seen in Figure One.
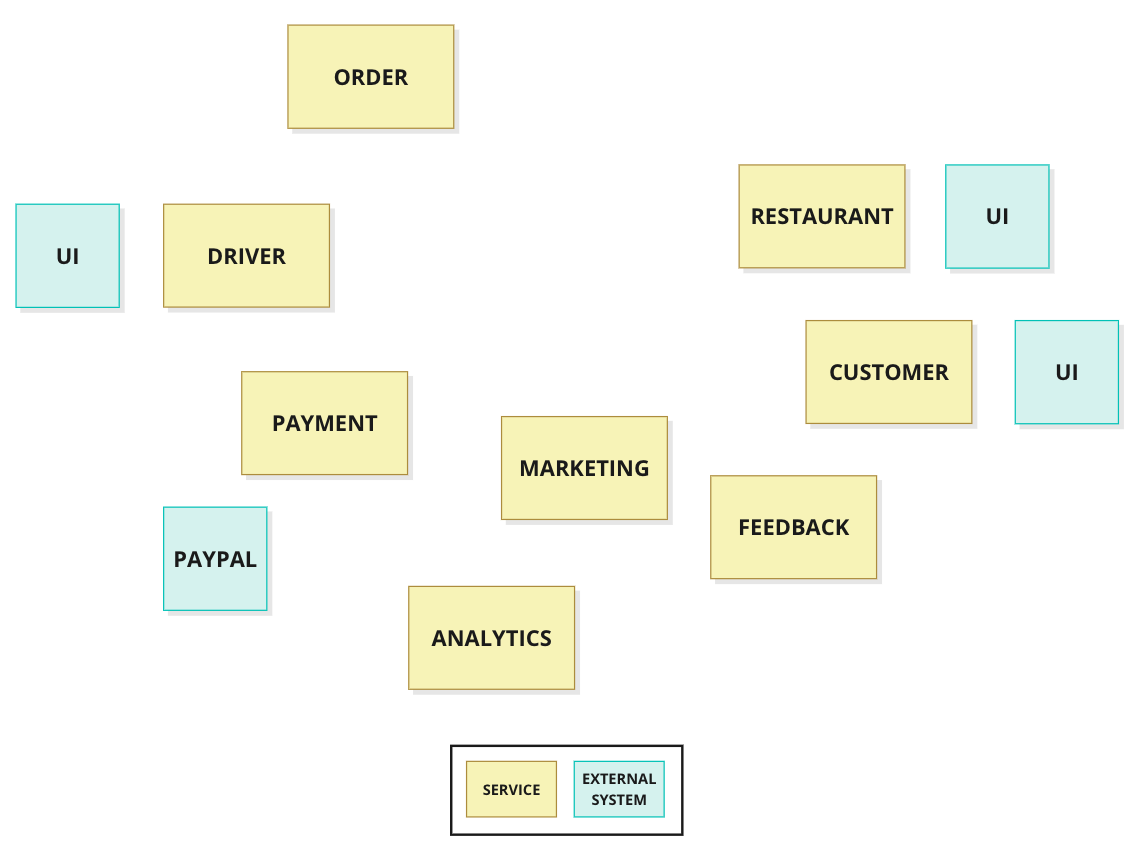
Figure One: Potential Microservices.
For our example, the working team has decided that the highest-value, simplest starting point is when an order is placed with a restaurant. The team diagrams out this process as seen in Figure Two.
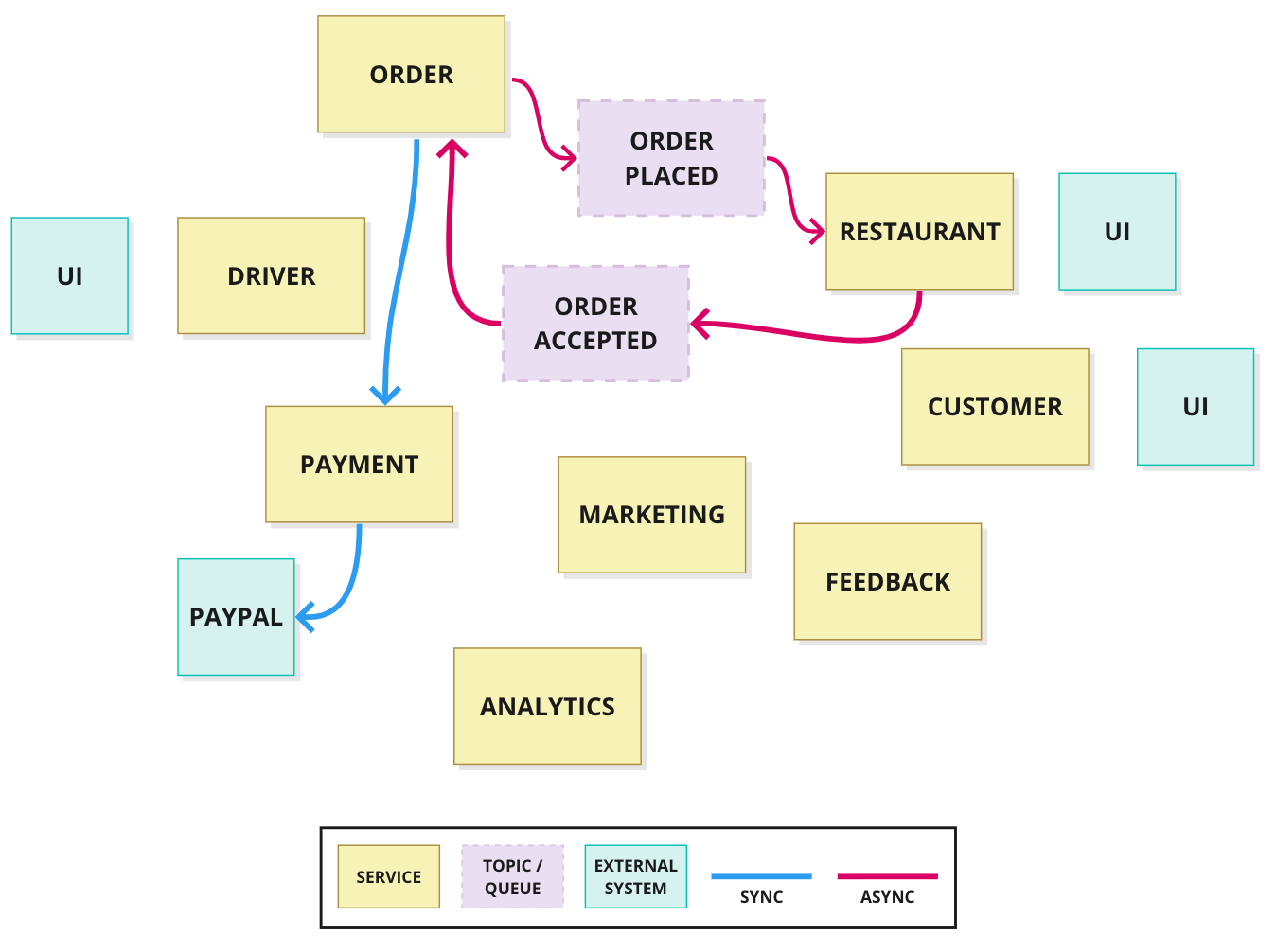
Figure Two: Order Placement Flow.
Let's look at this flow.
To start with, the restaurant needs to see the incoming order and then accept or reject the order. Once the order is accepted, then the payment can be processed.
To do this, the Order service needs to first notify the Restaurant service with the order details. According to the business stakeholders, this does not need to happen in real-time, so the working team has decided that this API call can be asynchronous—here indicated by a red line—and so the team will need to implement a queue. Here, you can also see a good example of how knowing the business context informs technical decisions, such as using async versus sync API calls.
With all of this, it’s easier to determine the user stories and the implementation strategy that the developers can start implementing:
-
The Order service should pass the order details to the Restaurant service.
-
The restaurant should be able to accept the order.
-
The Restaurant service should notify the Order service if the order is accepted or not.
-
If the order is accepted, the Order service should submit the order details to the Payment service.
-
The Payment service should submit the payment request to the payment provider.
Microservices implementation anti-pattern: Insufficient test automation
Modernizing apps is costly, both in terms of time and money. Or, rather, it only seems costly. What's actually costly is finding yourself in a situation where the business needs to add new functionality to your software, but to do so, you need to delay evolving the business so that you can first modernize the legacy architecture, which introduces delay and schedule uncertainty. People will be desperate to cut corners and speed up as much as possible, and testing is one of the first places they look. This is a common microservices modernization anti-pattern we see. This would be unacceptable in many other domains—for example, cutting back on safety testing for cars or baby formula isn't a good business idea, no matter how long testing takes.
One of the primary goals of breaking a monolithic legacy app into microservices is to make the app easier to build, maintain, and update. This is especially important when you have a large and complex application, multiple individuals and teams contributing, and a complex business process. This is already enough work without having to also deal with bugs that testing would have caught.
Testing is about more than just finding bugs, it's about speeding up your release cycles as well. If your system is one that consistently works as expected, it can be released to production quickly and predictably, and this requires discipline in the implementation of automated tests. These tests not only ensure that new features don’t break existing ones and can be deployed safely, but also serve as documentation on the functionality for future contributors.
At Tanzu Labs, we practice Test-Driven Development (TDD) and help our clients become experts in this discipline. In combination with other Extreme Programming practices like Pair Programming and CI/CD, you'll quickly see the benefits of your modernization work.
For example, one organization we worked with was trying to rebuild their customer-facing website, and 35% of the working team’s backlog was comprised of bugs. That led to increased delays, rising development costs, longer feedback loops, and made it almost impossible for the team to communicate predictable delivery estimates to stakeholders. The additional time to manually test features, and to manage and address bugs, led to release cycles in the order of months.
When we worked with the organization to co-deliver end-to-end functionality, including new middleware services, we built up their capability and discipline to apply practices like TDD. Within 12 weeks, their backlog was 0% bugs, we were seeing a release cycle reduced to weeks, and we achieved 100% accuracy on our delivery estimates. Two years later, the organization is still benefiting from this shift to TDD.
Clients who adopt these practices find that it streamlines the integration of new engineers into their teams due to better documentation and knowledge sharing. This also allows them to scale their operations much more effectively.
Microservices deployment anti-pattern: Big bang releases
Pushing new code to production invariably brings the risk that something will break and bring negative consequences. For some organizations,and certainly for operations teams whose necks are on the line, this means the less we touch production code, and the less frequently we deploy changes, the better. In many cases, so many risk management protocols have been put in place that it’s simply not worth the effort to push to production frequently. Teams practice the best way to reduce risk deployment failure: Don't deploy.
One major risk that we seldom see recognized is the risk of building the wrong thing, something that does not meet business needs or that is actually not easier to evolve to fit business needs. The only reliable way to validate whether the new modernized application is actually useful is to gather feedback from people using the software in production. As we've discovered time and time again, until people start using the software, you won't know if you've put in the right features or even chosen the right problems to solve. Therefore, the longer teams wait to deliver the new services and functionality, the more risk accumulates. And the cost in time of money of re-work can often be huge.
Instead, we work with customers to find ways to release smaller parts of the new software sooner. This lets them validate the new microservices architecture as we go. We do this in two ways:
-
By finding a thin slice of functionality across one or more services that is both valuable enough and small enough to feasibly deliver to users quickly for fast feedback. This may be equivalent to a user journey or an end-to-end business flow. There'll likely be several thin slices that are good candidates, and in those cases, we try to rank those similar candidates by asking questions that include: Which part of the process is causing the most friction to maintain and innovate on or could benefit from looser coupling? Or which is incurring the most impactful performance or security issues and could benefit from moving to the new platform? We might try using a tool like 2x2 prioritization to weigh business value against technical complexity and align on the first thin slice. For example, in the food delivery application example above, the first thin slice was placing an order at a restaurant. The team did not need to plan for handling the other business flows like payments and delivery immediately. Instead, they could start validating their assumptions and methods and then use that new expertise to modernize other parts of the system.
-
By putting in temporary integrations between the initial, modernized slices and the legacy systems so that the new microservices can be used in real business workflows. Once again, the delivery team can learn and gain expertise as they continue to incrementally modernize the rest of the application. This is often done with the Strangler Fig pattern.
By following this strategy with Hyundai, we were able to reduce their delivery time from 14 days to less than three. And, at the same time, we were validating that our approaches worked and avoiding the rework and delays that would have otherwise occurred..
The better path to app modernization
Let's use the above modernization anti-patterns as a foil to understand what successful app modernization projects look like. This is an incomplete list, but we believe that these steps are critical for success:
-
Focus on the goals—Throughout this process, it's essential to keep the desired modernization goals in mind. Whether it's enhancing the ease of adding features, simplifying maintenance, achieving faster deployments, or improving performance and security, these objectives guide the decision making.
-
Start with the business need—The app modernization journey begins with a deep dive into the business domain to understand current and changing business needs. In this phase, it's vital to involve business owners to make sure that the architectural design aligns with the specific needs of the business.
-
Practice Test-Driven Development (TDD)—As the modernization project progresses, test automation becomes a crucial component, facilitating fast feedback loops and ensuring that the system functions as expected.
-
Release early, often, and small—When incremental deployment is embraced, changes can be released and validated gradually, reducing the risk of disruption.
-
Build trust with working code—Demonstrating value early in the modernization journey is a critical step. By showcasing tangible results, trust is built, which bolsters confidence in the approach and encourages continued success.
If you would like to know more about Tanzu Labs’ approach to application modernization, how our experienced practitioners help enable customer teams to unlearn their legacy approach, and how to adopt modern practices by applying them in context, please get in touch with us.





















