

Data-driven innovation needs a platform that allows you to harness the full potential of data analytics and machine learning. In this series you’ll discover a roadmap for architecting a data science platform using VMware Tanzu. We'll delve into the building blocks of a successful platform to drive data-driven insights. So far we’ve covered:
Part 1 - The data science platform revolution
Part 2 - Data collection and management
Part 3 - Data processing and transformation
Part 4 - Harnessing the power of models
Whether you're architecting a new platform or optimizing an existing one, join us as we explore how to create sophisticated data science environments that foster innovation, efficiency, and growth. Here, we'll explore the model deployment and operationalization layer of the data science platform.
Activating model-driven decisions
Even the most brilliant models languish in the lab without a good deployment plan or path to production. Data-driven insights deliver business impact only when put into action making a smooth, repeatable, scalable and secure path to production critical to the success of your models.
Building upon discoveries made during analysis and modeling, the deployment and operationalization stage turns potential into tangible results. But putting data science into action is not easy, especially without incorporating automation and data transformation services.This phase integrates predictive models into decision engines, automated systems, and the services that redefine industries. It demands vigilance for data shifts, regulatory compliance, ethical use, and continuous monitoring for building trust. While operationalization empowers insights to redefine what businesses can achieve, challenges from scaling to navigating regulatory compliance can slow down or even stymie your ability to turn potential into action.
Fig 1.0: Conceptual Data Science Platform
Streamlining and Scaling: Critical challenges in deploying ML models
Deploying and operationalizing machine learning models is a multifaceted process fraught with unique challenges. Understanding these hurdles is the first step toward the development of effective strategies for overcoming them.
Model scalability and performance: Models that work flawlessly on small datasets and limited user interaction can face challenges in production. As models are deployed into production, they are expected to process significantly larger volumes of data than during the training phase. Issues such as latency, an inability to handle large volumes of data, and performance degradation with new input types are common culprits. Production models often need to serve predictions to a large number of users simultaneously. Ensuring consistent performance under such concurrent demand is a challenge, particularly for complex models that require substantial computational power. The ability to dynamically scale resources in response to fluctuating demand is essential to maintain performance without incurring unnecessary costs during periods of low usage. For example, an e-commerce recommendation engine may struggle under the volume of shopper and product data during peak sales season, leading to slow or irrelevant recommendations.
CI/CD for machine learning models: Manual, ad-hoc deployment processes hinder efficiency and increase the chance of errors occurring. CI/CD pipelines customized for ML workloads are indispensable, as these pipelines automate testing, data and model versioning, and model deployment to enable smooth model updates and ensure consistency across environments. Version-control poses a challenge for both the model and its underlying data , as data can be large and change frequently. Implementing version control requires solutions that can handle not just the code, but also datasets and model artifacts. Automated testing for models must include data validation, model training, and evaluation to ensure confidence that the model meets predefined performance benchmarks before deployment. Adopting MLOps practices, which blend ML, DevOps, and data engineering, can address many of the challenges associated with CI/CD for ML models. MLOps focus on automating the ML lifecycle, from data preparation to model deployment and monitoring, ensuring a smooth transition between each phase. Utilizing specialized MLOps tools like Kubeflow can significantly streamline this process.
Collaboration between data science and operations teams: Misaligned goals and miscommunication between data scientists and IT operations can create bottlenecks and frustration. Misaligned tools, workflows, and even terminology between data scientists (often experimental) and IT operations (stability-focused) lead to friction. Fostering effective communication and establishing well-defined workflows that span both data science and operations teams is crucial to deployment success. Teams need to align on expectations, performance metrics, and processes for rapid problem resolution.
Regulatory compliance and data privacy: Operating in regulated industries adds extra complexity, as meeting data handling standards such as GDPR or HIPAA cannot be an afterthought. Models in finance, healthcare, and other highly regulated areas must be designed from the ground up with privacy and accountability in mind. Tracking data lineage, maintaining rigorous security protocols, and facilitating audits are essential, not optional.
When addressing the core challenges of deploying and operationalizing machine learning models, organizations need a cohesive strategy that encompasses both technological solutions and collaborative practices. By leveraging scalable architectures, fostering effective communication between teams, and integrating comprehensive testing and version control mechanisms, organizations can enhance the efficiency, reliability, and impact of machine learning initiatives.
Tools and platforms that support these efforts, including those offered by VMware Tanzu, are invaluable resources for navigating the complexities of bringing machine learning models from development to production.
The Future of ML Operations: A Tanzu-driven approach
Operationalizing machine learning isn't merely a question of the models themselves. Bridging the gap between data scientist experimentation and the continuous monitoring, updates, and governance demanded by production systems introduces unique complexities. The VMware Tanzu suite addresses these hurdles head-on by providing a platform for streamlined CI/CD, proactive model health monitoring, and collaborative workflows.
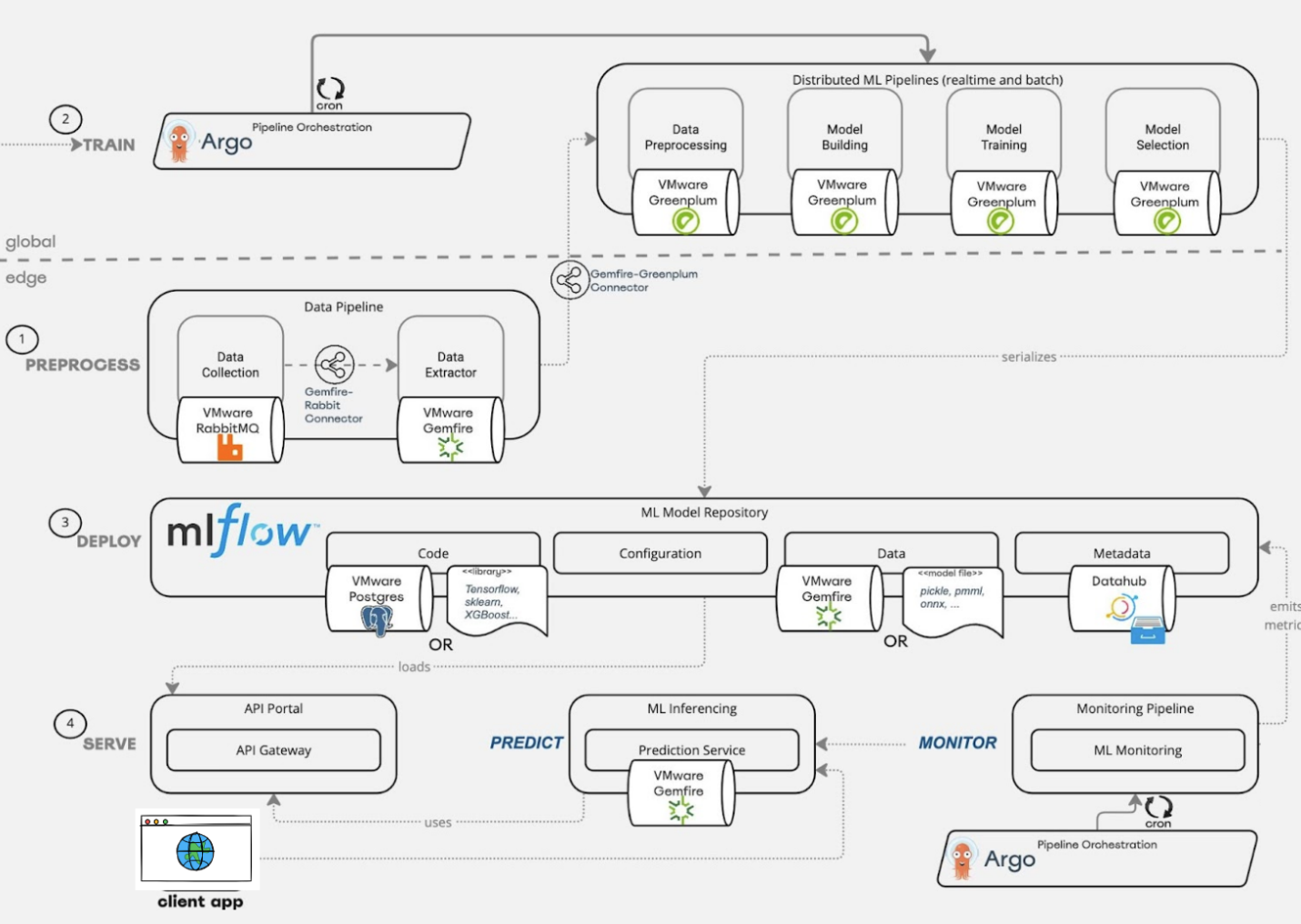
Fig 1.1: Model Deployment & Operationalization with Tanzu
Scaling models to meet real-world demands: Built on Kubernetes, VMware Tanzu dynamically scales computational resources up or down to prevent bottlenecks. VMware Tanzu Kubernetes Grid (TKG) handles intelligent container distribution and scaling for seamless responsiveness even during sudden peaks. Data scientists and operations teams benefit from Kubernetes features. such as Horizontal Pod Autoscaling (HPA) to adjust replica counts without downtime. For more granular control, you can base scaling decisions on custom metrics related to latency and throughput, which allows models to remain fast and accurate across usage spikes and troughs and eliminates frustrating slowdown during crunch times. Your infrastructure aligns with actual needs—paying only for what you use during high volume periods, while automatically saving when less capacity is required. With Tanzu, teams focus less on frantically provisioning resources during crashes and more on the strategic advancement of machine learning models.
Streamlining the ML deployment lifecycle with CI/CD and MLOps: Tanzu enhances the machine learning lifecycle with robust CI/CD capabilities, automating everything from model testing and validation to deployment and updates. This automation ensures consistency, reduces errors, and accelerates the delivery of enhancements and new features by integrating best-of-breed MLOps platforms—Kubeflow, Domino Data Labs, and others. Together, these solutions enable robust model deployment practices. Kubeflow streamlines complex ML workflows through pre-built and customizable pipeline components. Pipelines enforce predictable steps and testing regimes to minimize costly mistakes and increase confidence in production releases. It also automates steps that include data validation, model training, and deployment. Domino Data Labs enables a unified workspace for effortless model and experiment tracking, which supports the easy rollback to previous versions if problems arise in production. Automated processes dramatically reduce the time between model development and deployment. Experiment tracking and clear model lineage create greater trust by providing visibility into how a model reached its current state.
From riction to Flow: Building the collaborative ML lifecycle: Tanzu transforms the collaborative machine learning lifecycle by turning potential friction points into streamlined workflows. As a shared platform that supports unified workspaces, streamlined CI/CD pipelines, and enhanced communication, Tanzu empowers teams to work together more effectively, from model development through deployment. Tanzu encourages practices that enhance team collaboration, such as DevOps and MLOps methodologies, and integrates data science into the broader application lifecycle. This approach not only improves operational efficiency, it also fosters a culture of shared responsibility and continuous improvement.
By integrating Tanzu Application Service (TAS) and Tanzu Application Platform (TAP) with support for application accelerators and internal developer platforms, data scientists and operations teams can work within the same ecosystem. This results inin a more agile, efficient, and cohesive process that accelerates the delivery of machine learning innovations to production and drives meaningful business impact.
Navigating regulatory compliance and data privacy: Tanzu aids compliance efforts by providing strong security measures, audit capabilities, and the flexibility to leverage specialized third-party compliance solutions as needed. Tanzu Guardrails can empower cloud operations and application teams with expanded visibility into governance issues and deeper insights into overall operational and compliance risks across public cloud environments. It can also provide a description of violated policies as well as suggest remediation steps for each finding to help make resolvingf compliance issues easier. Tanzu provides tools for data at rest encryption and secure transport in production. It can create fine-grained role-based access to both data and models by adhering to the principle of least privilege, and can integrate with common audit log management or industry-specific compliance platforms to streamline workflows.
Revolutionizing Customer Engagement: A case study on advanced model deployment
In a groundbreaking initiative, one leading telecommunications company embarked on a mission to redefine its approach to customer retention and engagement. With an increasingly competitive market and rising customer churn rates, the company turned to predictive analytics to transform its marketing strategies.
As the organization grappled with the complexities of managing and processing vast volumes of customer data generated from diverse sources, integrating transactional data, customer interaction logs, and social media feeds into a cohesive analytical framework was no small feat. Moreover, ensuring the accuracy, completeness, and reliability of this data was paramount to building effective predictive models.
The company recognizing the need for a robust technical infrastructure, and leveraged VMware Tanzu's suite of technologies to operationalize its churn prediction and Next Best Offer (NBO) models. Greenplum was key to the solution, serving as the central data repository and handling large-scale data workloads with unparalleled efficiency. However, the true innovation lay in how the models were deployed and made accessible across the organization. Kubeflow on Tanzu Kubernetes Grid (TKG) streamlined the orchestration and deployment of these models , marking a significant advancement in the company's machine learning operations (MLOps). This setup not only ensured that models were scalable and resilient, it also facilitated continuous improvement through regular updates and retraining, and by addressing the ever-evolving landscape of customer behavior.
It was essential that omni channel marketing teams could use these models to craft experiences to retain customers. The organization exposed its churn prediction and NBO models as APIs through Tanzu Application Platform (TAP) to democratize access to predictive insights for various departments. The deployment and operationalization of churn prediction and NBO models via TAP marked a significant leap forward in how the organization approached marketing. It equipped marketers with the tools to not only predict customer behavior, but to also act on these predictions in a manner that is both strategic and scalable. TAP’s ML accelerators provided application development teams with the necessary framework to seamlessly consume these models into application workflows. It also enabled application developers and data scientists to work seamlessly all the way from experimentation to deployment and operationalization. The result is a marketing strategy that is proactively aligned with customer needs and preferences while driving satisfaction, loyalty, and revenue. Today, marketing campaigns are more targeted and personalized, significantly improving customer retention rates, and the insights derived from the models enable the marketing team to proactively address customer needs for enhanced satisfaction and loyalty.
This case study exemplifies the transformative potential of deploying and operationalizing machine learning models at scale. The telecommunications company not only navigated the challenges of data volume, velocity, variety, and quality, but also set a new standard for strategic marketing in the industry. By embracing VMware Tanzu, the organization showcased a blueprint for success in the digital age, underscoring the critical role of advanced data analytics in driving business outcomes.
Operationalizing ML: Keys to success
We've explored the hurdles to deployment and operationalization, as well as how Tanzu helps overcome them. Now, let's recap some key takeaways for organizations that want to ensure that ML projects maintain momentum and evolve into tangible business value.
-
Scalability is non-negotiable: Models must adapt to meet real-world demand fluctuations for continued accurate results.
-
Streamline deployment with MLOps: CI/CD best practices tailored for machine learning significantly reduce errors and minimize the time needed to update modelst.
-
Fostering collaboration is critical: Successful operationalization demands that data science and operations teams effectively work together through shared workspaces and enhanced communication.
-
Compliance first: Industries governed by regulations should proactively integrate strong data security and audit tools right from the beginning for smooth deployment
-
Monitor performance: Detecting performance drifts early avoids silent failures, which is why organizations should remain vigilant when tracking key metrics, proactively setting alerts, and integrating feedback loops to maintain and improve model accuracy.
The Tanzu platform, combined with integrations tailored to MLOps (Kubeflow, Domino, etc.), provides solutions to alleviate these key pain points. From streamlining deployment pipelines to facilitating team collaboration and handling scaling needs, Tanzu enables organizations to successfully operationalize data science workflows.
Read the other posts in this seres, where we cover:
Part 1 - Data science platform revolution
Part 2 - Data collection and management
Part 3 - Data processing and transformation
Part 4 - Building innovative ML models
Part 5 - Deployment and operationalization of models
Part 6 - Monitoring and feedback
Part 7 - Principles and best practices: From data to Impact
About the Author
Follow on Linkedin More Content by Pradeep Loganathan



















