

A robust platform is essential to fueling data-driven innovation and harnessing the full potential of data analytics and machine learning. This blog series provides a roadmap for architecting a data science platform using VMware Tanzu. We'll delve into the building blocks of a successful platform that drives data-driven insights. So far we’ve covered:
Part 1 - Data science platform revolution
Part 2 - Data collection and management
Through this series, we'll dissect the architectural decisions, technological integrations, and strategic approaches that underpin successful data science platforms, all while highlighting Tanzu's pivotal role in this transformative process. Whether you're architecting a new platform or optimizing an existing one, join us as we explore how to create data science environments that foster innovation, efficiency, and growth.
In the third blog in our series, we'll focus on the data processing and transformation layer of the data science platform.
From raw data to refined insights
Patient outcomes are at the heart of healthcare. Imagine a healthcare provider striving to improve patient outcomes while managing costs. The provider possess years of patient records, treatment outcomes, epidemiological research, demographic information, and real-time health monitoring data. Each dataset offers a piece of the puzzle when understanding patient health patterns, unlocking broader health trends, predicting health issues, and optimizing treatment plans. However, this critical data is scattered across different systems, each with its own format, standards and structure. This not only makes it challenging to fully harness these insights, it also hinders proactive and comprehensive care because patterns remain hidden, treatment plans are ineffective, and resources are wasted on initiatives that fall short. This scenario exemplifies the crucial stage we explore in the Data Processing and Transformation chapter of this data science platform series.
In the previous chapter of our exploration, we delved into the anatomy of a data science platform and laid the groundwork by examining the critical role of data collection and management—the very bedrock upon which all data-driven innovation is built. Having already established robust data collection and management capabilities with Tanzu, we now shift our focus to a transformative stage in the data science workflow. To harness the true potential hidden in this trove of data, data requires refinement and reshaping. This layer bridges the gap between raw data and the actionable discoveries needed to make data-backed decisions, improve efficiency, and enhance customer or patient experiences.
Data scientists and engineers know that untapped data holds the key to answering an organization's most pressing questions. But, turning those 'what-ifs' into strategic realities demands innovative thinking.
Imagine easily blending real-time health monitoring data with years of treatment outcomes, or pinpointing equipment failure patterns by processing massive operational logs alongside maintenance schedules. This is the power of seamless data processing and transformation primed for maximum impact.
In this phase, the raw, often chaotic store of data is refined into a structured, coherent form that is ready for in-depth analysis and modeling. Here, we meticulously reshape, enrich, and manipulate data using sophisticated techniques such as attribute construction, discretization, normalization, and more to help reveal patterns and uncover trends relevant to specific business objectives. The value of data sets increases substantially in this phase, preparing the groundwork for powerful analysis, advanced modeling, and impactful visualizations that enable confident, data-informed choices.
Scaling Heights and Bridging Gaps: Core challenges in data processing
Data professionals often grapple with several pain points in this phase. These challenges can jam up the analytics process, delaying insights and hampering decision-making. Some of the challenges we’ve witnessed across our customer base include:
Scalability and performance: As data volumes continue to grow exponentially, the ability to efficiently process and transform this data becomes a significant challenge. In a world of exploding data volumes, traditional tools choke on the sheer size of datasets. This bottleneck affects everything from simple data cleansing operations to complex feature extraction, leaving data engineers with the options of either sacrificing the richness of data for speed, or enduring prolonged processing times that render insights obsolete. Operations such as joining massive datasets, data transformations, or statistical feature creation can slow to a crawl or fail outright on traditional setups, which means that data engineers often face an impossible choice: Down sample and risk missing crucial insights, or wait days for basic transformations that result in crippling downstream analysis.
We can see how this can hamper experimentation, as each what-if question, iteration, or refinement can take hours or even days. This makes it difficult, if not impossible, for data scientists to create an interactive process with fast feedback-loops, which ultimately cripple innovation. In fast-moving markets, data insights quickly become stale, and the inability to move quickly and continuously improve your decisions can lead to costly delays that erode the value of insights—turning real-time opportunities into outdated analysis. The real-world impact is stark. For instance, cybersecurity teams analyzing terabytes of log data to detect threats face a race against time, where delays can mean the difference between thwarting an attack and a costly breach.
Complex data integration: Data silos hold insights hostage, and data engineers face significant technical and logistical challenges integrating data from disparate sources into a cohesive, analytics-ready format. This includes dealing with various data types (structured, semi-structured, and unstructured) and sources (internal databases, cloud storage, IoT devices, etc.). Adding to this complexity is the temporal aspect of data, encompassing real-time, streaming, and historical datasets, each requiring distinct handling and integration approaches to unlock their full potential. Each might have its own formats, inconsistencies, and varying degrees of quality.
Imagine trying to accurately predict equipment breakdowns to create maintenance schedules. Data scientists, instead of focusing on building predictive models, are forced to wrangle maintenance logs (structured), sensor data (semi-structured), and weather data (unstructured)— each trapped in separate systems and riddled with inconsistent formats and potential quality issues. Without data processing and transformation to unify these sources, comprehensive analysis remains impossible. This fragmented landscape robs organizations of the insights needed to optimize operations and transition from reactive to proactive maintenance strategies.
Feature engineering: Feature engineering is a crucial step in the data science process, especially in the fields of machine learning and predictive modeling. Feature engineering is the process of using domain knowledge and data manipulation techniques to transform raw data into features that can be directly used by machine learning models. At the heart of effective data processing is the ability to extract meaningful features that can be used to build predictive models—aw data seldom aligns perfectly with the needs of predictive models. This phase encompasses the creative derivation of informative features (such as aggregated variables, text sentiment scores, or time-series patterns) by leveraging specialized domain knowledge, diverse transformation techniques, and a deep understanding of modeling requirements. Lack of proper feature engineering leads to subpar model outcomes. Collaboration between subject matter experts, data scientists, and data engineers can stall as their different toolsets make domain knowledge sharing an arduous process.
A fitting illustration for this is in fraud detection, where converting transaction histories into features that highlight frequency, identifying geographic anomalies, or detecting subtle deviations in spending patterns are essential. This transformation is a quintessential task of feature engineering, showcasing its role in converting disparate, raw data into coherent, model-ready formats.
Successfully navigating this challenge not only elevates the predictive accuracy of fraud detection models, it also underscores the importance of feature engineering in uncovering critical insights from across data silos. Insights that were once obscured become accessible, empowering organizations to make strategic decisions and achieve a comprehensive understanding of theoperational landscape. Effective feature engineering is indispensable for any organization seeking to fortify its data science capabilities, bridging the gap between raw data and actionable intelligence.
From Silos to Insights: Tanzu’s pathway through data complexity
Data trapped in isolated silos, time-consuming manual manipulations, and restrictive bottlenecks limit the full potential of data assets for strategic optimization and insights. The challenges of data wrangling, scaling constraints, and the intricacies of feature engineering in the ata processing and transformation phase keep organizations from fully capitalizing on their data assets. Tanzu offers a suite of tools and capabilities specifically designed to overcome these hurdles, accelerating the path to transformative insights.
Data transformation at scale with Tanzu Greenplum: Tanzu Greenplum already plays a pivotal role in streamlining access across disparate data sources in the foundational layer. Greenplum supports data federation, allowing it to semlessly access and integrate data from multiple sources. Using the Platform Extension Framework (PXF), Greenplum can query external data in multiple formats and locations, across cloud storage objects, data lakes, SQL/No SQL databases, streaming data with Kafka, Spark, and many others. This capability enables organizations to perform joins and transformations across data that resides in different databases or data stores, without needing to physically move the data into a single location. It utilizes a distributed, massively parallel processing (MPP) architecture that allows for high-performance execution of complex data transformations and joins across very large datasets. The architecture enables the system to distribute the workload evenly across all available resources to improve query performance and data processing speeds. It also supports the creation of custom User-Defined Functions (UDFs), which can be written in various programming languages such as Python, R, and Java, allowing data engineers and scientists to implement custom logic and complex analytical functions directly within the database.
Fig 1.1: Data processing with Tanzu Greenplum
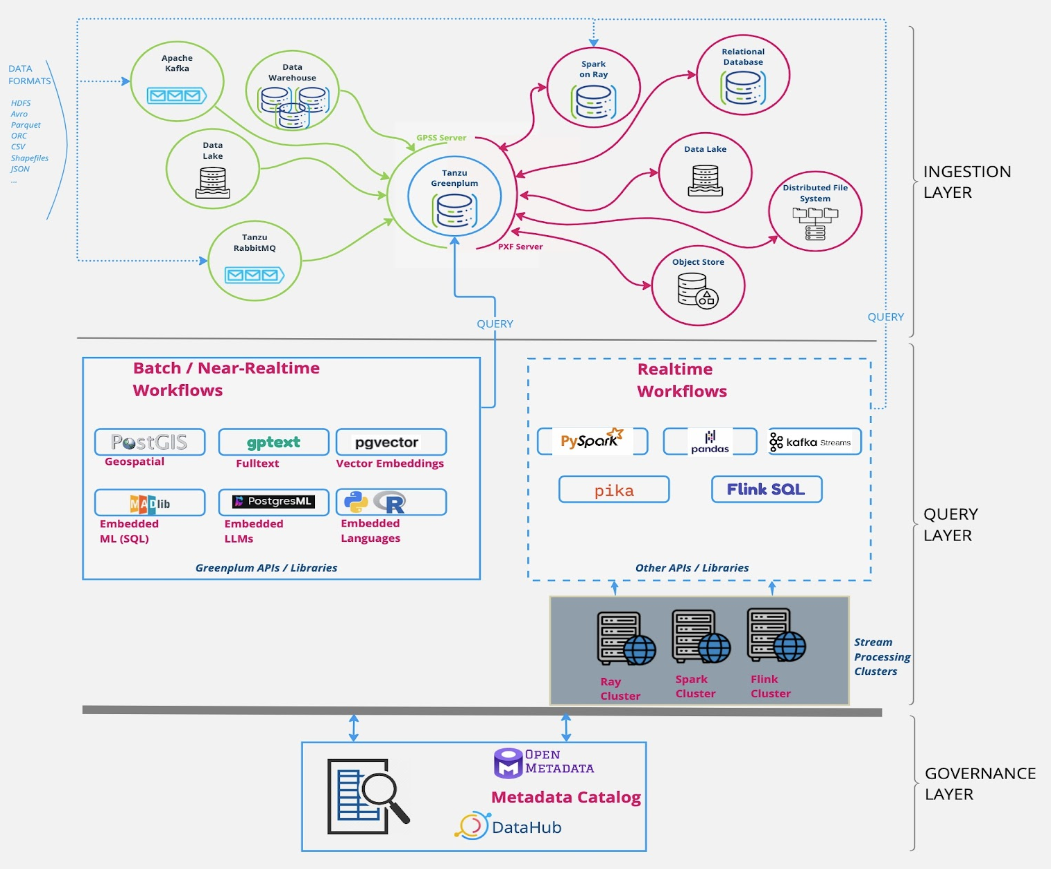
Scaling operations on Tanzu Kubernetes Grid: Tanzu Kubernetes Grid combats bottlenecks created by demanding data processing operations across massive datasets. It empowers data scientists with the flexibility and computational power needed for demanding transformations. Whether you’re leveraging familiar libraries (such as scikit-learn for statistics) or scaling purpose-built ETL tools, containerization provides on-demand compute power while fostering collaboration among teams using varied skill sets. Increased processing speeds directly benefit data scientists and powers rapid iteration, supporing experimentation in a nimble, responsive manner.
Streamlining data-driven optimization: Beyond data processing, Tanzu's ecosystem includes tools like Tanzu Data Services, which are designed to enhance the flow of data within an organization. Tanzu Data Services, such as Tanzu RabbitMQ, integrate seamlessly with data workflows foraccess to fresh operational data or external market factors. By enabling the real-time collection, processing, and analysis of data, these services ensure that decision makers have access to the most up-to-date insights. This real-time capability is crucial for applications that require a near-instantaneous understanding of data, such as fraud detection or personalized customer experiences. This fuels optimization-enabling models that require a near-real-time view to maximize their potential.
A Leap in Efficiency: Basel III stress testing reimagined with Greenplum
Stress testing and risk asset reporting under Basel III are critical components of a financial institution's risk management and regulatory compliance framework. These processes are designed to ensure that financial institutions are resilient to financial shocks and have adequate capital to cover risks under various adverse conditions. Basel III reporting is applicable globally and across a wide range of jurisdictions that are members of the Basel Committee on Banking Supervision (BCBS). The Basel III framework requires that stress testing and risk asset reporting be performed regularly, with the frequency often dictated by the regulatory authorities in each jurisdiction. Financial institutions are typically required to submit regulatory reports to demonstrate Basel III compliance on a quarterly or monthly basis, or sometimes even more frequently. Compliance with these standards requires banks to maintain detailed records, perform intricate calculations, and report in a manner consistent with regulatory expectations. There are several factors contributing to the complexity and time-consuming nature of these tasks.
Data challenges: Financial institutions handle and analyze vast amounts of data that span multiple years. This data includes various asset classes, each with its unique risk characteristics, transaction histories, and customer information. What makes this even more complex is the need to aggregate and reconcile data from different sources and systems within the bank. Ensuring data accuracy, consistency, and completeness is a massive challenge, as data may need to be sourced from disparate systems and reconciled.
Processing pipeline complexity: Processing pipelines play a pivotal role in streamlining the complex and time-consuming tasks of Basel III stress testing and risk asset reporting. Pipelines extract data from various databases, file systems, and external sources (including market data providers and credit rating agencies). They implement rules and transformations to ensure data is accurate, consistent, and in the correct format for downstream calculations. This may involve handling missing values, correcting errors, and mapping data to standard taxonomies. Complex stress tests and risk asset calculations are divided into smaller, modular steps within the pipeline, and pipeline stages can be executed in parallel across multiple compute resources to significantly accelerate processing time.
Computational demands: The calculations for risk-weighted assets (RWAs) and potential losses under stress scenarios are highly complex. They involve numerous variables and assumptions about future economic conditions, interest rates, market volatility, and default rates. Running complex analytical processes with massive datasets demands powerful computing resources.
In a real life example of the challenges created by this complexity, a global financial services provider was faced with the need to ensure the timely compliance with Basel III regulatory reporting requirements. Inconsistent formats across its legacy sources necessitated time-consuming reformatting and reconciliation, further hindering efficiency. The existing system, reliant on legacy databases and file systems, required multiple overnight batch processes due to the time-intensive nature of running calculation procedures, thereby delaying reporting and limiting the ability to respond promptly to compliance demands. Failure of even one of these processes resulted in a cascading effect, thereby delaying reporting and limiting the ability to respond promptly to compliance demands. The organization needed to streamline its compliance reporting and stress testing processes to adhere to Basel III reporting timelines.
To overcome these challenges, the financial services provider opted to implement risk asset calculation and stress testing on the advanced Greenplum database platform. This strategic enhancement enabled the processing of three years' worth of data in under one hour, a significant leap in efficiency compared to the cumbersome procedures previously in place. This solution not only dramatically accelerated the process of generating compliance reports and conducting stress tests, it also ensured that the financial services provider could successfully meet Basel III requirements on-time, every time.
Solidifying Data's Potential: A bridge to advanced insights
Through targeted data processing and transformation, organizations turn vast repositories of raw data into strategic assets. This crucial stage extracts essential metrics, enhances predictive model reliability, and unlocks informed, data-driven optimization across business operations. The transformative potential of analytics becomes possible as a result of data refinement. Tanzu facilitates this process by simplifying complex manipulations, scaling computational performance, and fostering interdisciplinary collaboration in a unified workspace.
With well-structured, relevant, and clean data in hand, we're prepared to delve into the power of advanced analytics. However, ata analysis and odeling encompasses more than simply statistical rigor. This critical stage necessitates careful algorithm selection, responsible model usage, and the creation of meaningful visualizations to communicate insights. To fully harness this wealth of structured data and glean strategic insights, a powerful set of analytical tools is essential.
Read the other posts in this seres, where we cover:
Part 1 - Data science platform revolution
Part 2 - Data collection and management
Part 3 - Data processing and transformation
Part 4 - Building innovative ML models
Part 5 - Deployment and operationalization of models (coming soon)
Part 6 - Monitoring and feedback (coming soon)
Part 7 - Principles and best practices (coming soon)
About the Author
Follow on Linkedin More Content by Pradeep Loganathan



















