

A robust platform is essential to fueling data-driven innovation and harnessing the full potential of data analytics and machine learning.
This blog series provides a roadmap for architecting a data science platform using VMware Tanzu. We'll delve into the building blocks of a successful platform. So far, we've covered:
Part 1 - Data science platform revolution
Throughout this series, we'll dissect the architectural decisions, technological integrations, and strategic approaches that underpin successful data science platforms, as well as Tanzu's pivotal role in this transformative process. Whether you're architecting a new platform or optimizing an existing one, join us as we explore the creation of data science environments that foster innovation, efficiency, and growth.
In the first of the posts in this series we provided an overview of the attributes of a data science platform. In this the second post in the series, we'll focus on the data collection and management layer of the data science platform.
Building strong foundations
Organizations are witnessing an unprecedented surge in data generation. Customer activity— on websites and apps, from sensor readings, financial transactions, and social media chatter—create a volume and variety of data that is rarely uniform. Every interaction, transaction, and digital footprint contributes to this growing data deluge, creating both immense opportunities and significant challenges. This potential treasure trove contains valuable patterns, but only if an organization possesses the means to effectively capture and control data. The insights that drive better decisions often stay locked within this raw data if an organization can’t efficiently collect, manage, and secure it.
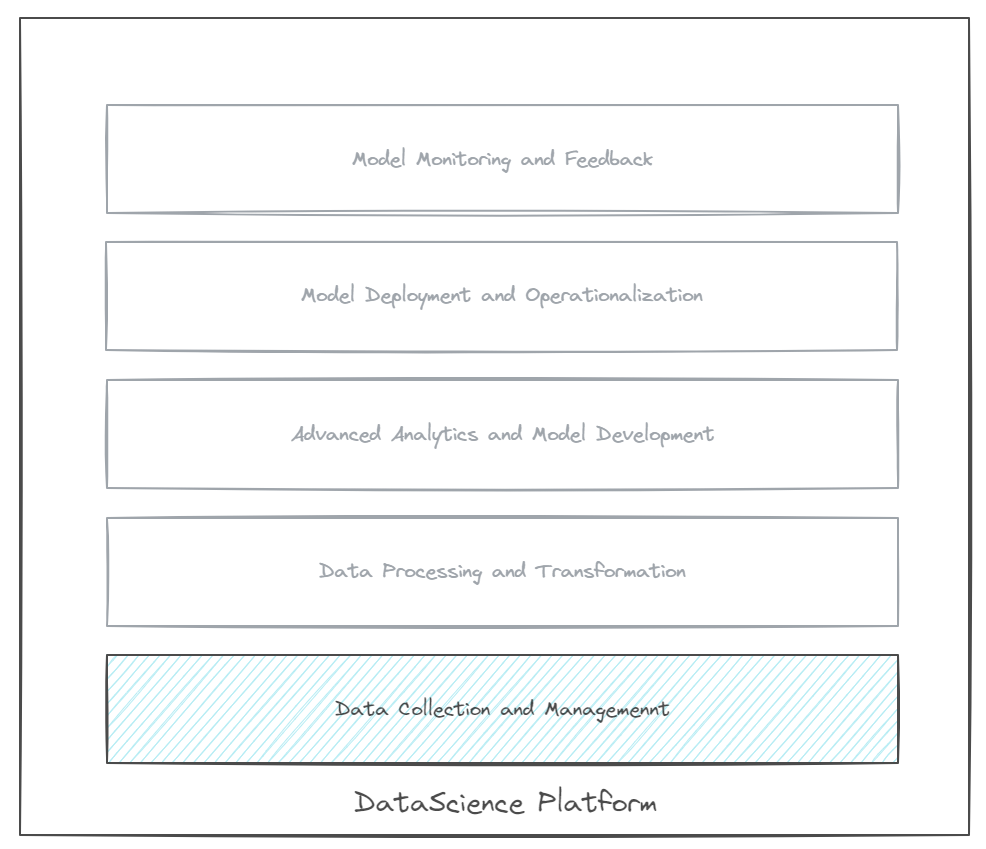
Fig 1.0: Conceptual Data Science Platform
Today's digital systems are built to consume and create data for better decision making and service, not to mention security and stability. This surge of information creates a constant dilemma for businesses: How to easily transform this wealth of data it into knowledge that improves decision-making. Raw data, even when plentiful, rarely arrives in a ready-to-analyze package. It must be captured, cleaned, and unified to fulfill its potential. Data engineers understand this challenge, which is why the first hurdle to building a successful data science platform is effective data collection and management.
Raw data is typically siloed across legacy systems, scattered in mismatched JSON files, and flooding in from real-time sensor feeds. It's a chaotic landscape where wrestling with fragmented data sources threatens to derail projects before they even begin. This deluge brings a wave of demands—unify the sprawl, handle growing volume and variety, and make it all readily usable and secure before the next audit rolls around.
Many data science initiatives become derailed before they reach production due to challenges associated with ingesting, processing, and securing data. Without clean, accessible, and secure data stores, even the most advanced algorithms and skilled analysts will struggle to produce reliable results. This foundational layer lays the groundwork, ensuring the quality, accessibility, and security of data, while setting the stage to unlock business-changing insights. This layer is not merely about accumulating vast amounts of data. It’s about laying the foundation for a data-driven culture that harnesses information to drive innovation, efficiency, and competitive advantage.
Data at Scale: Challenges of diversity, growth, and security
Data collection and management is fraught with challenges that can derail even the most well-intentioned data science initiatives.
Data silos hinder insights: Modern organizations collect data from a myriad of sources—CRM, ERP, custom applications, social media platforms, IoT devices, and more. Each source can have its own format, structure, and frequency of data updates, which makes it difficult to create a unified view of information. Consolidating data for comprehensive analysis poses significant integration challenges, causing delays in insights and project execution and creating frustrating limits when attempting to answer core questions that necessitate data from many sources. One example of this scenario occurs when seeking to understand why certain customer segments churn while others stay loyal, an analysis that often requires blending demographics, purchase behavior, and even website navigation patterns.
Managing data growth and variety: Data growth presents a multifaceted challenge because organizations now operate in an environment far beyond neatly structured databases. Unstructured text from reviews, social media, or call center transcripts holds potential insights, but also requires distinct collection and processing methods. Furthermore, the rise of real-time data sources (like e-commerce transactions or IoT sensor readings) demands platforms that are capable of ingesting and responding to events without significant lag time. Failure to adapt limits businesses to only reacting to past trends, rather than capitalizing on real-time insights to proactively shape their future.
Ensuring governance, security, and compliance: As data volume expands, so does the challenge of effectively managing this expansion with adequate governance and security. Organizations that are focused on leveraging data for strategic benefits must also ensure that responsible handling and secure storage are prioritized from the outset. Stringent regulations govern sensitive customer data, financial records, or healthcare information and reaquire that data collection and management platforms uphold strict access controls, audit trails for data lineage, and data quality safeguards. Non-compliance carries far-reaching consequences—not only hefty fines but also substantial brand damage and loss of customer trust. Data engineers shoulder the burden of ensuring that data is used responsibly and securely by implementing access controls, tracking data lineage for auditability, and enforcing compliance with evolving regulations that include GDPR, CCPA, PIPL, PDPA and others. Balancing these safeguards with the need for flexible data use and analysis is a constant challenge. When compliance is done right it not only avoids risk, it also creates a foundation of trust that enables your organization to confidently explore new data-driven initiatives. As our colleague Bryan Ross wrote last year, compliance should be treated as a feature, not a bottleneck. You can read more about that here.
Organizations that want to harness the full potential of their data assets need a cohesive strategy that is empowered by an integrated suite of tools. This is essential for efficient data management and a strong foundation for the data-driven initiatives that propel businesses toward innovation and competitive advantage.
Taming the Data Deluge: Your Tanzu toolkit
Data engineers face daily battles with scattered data sources, systems straining under the onslaught of new data, and the ever-present need to ensure security. VMware Tanzu offers a suite of integrated solutions designed to empower data engineers by helping them manage data at scale, accelerate insight delivery, and uphold data governance best practices.
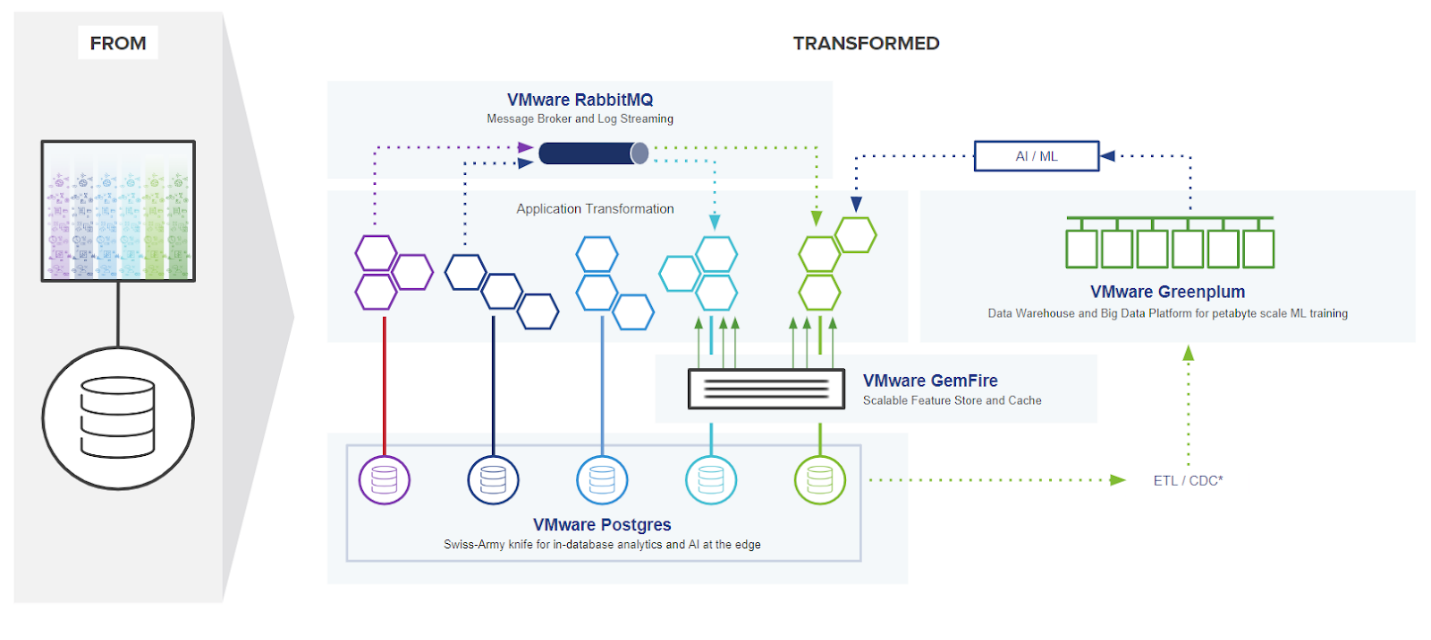
Taming data sprawl with Tanzu Greenplum: Tanzu Greenplum unifies disparate data sources within a single, high-performance analytics platform. With a massively parallel processing database that excels in handling large volumes of data across different types, Tanzu Greenplum distributes queries across disparate systems. This gives analysts a unified view without time-consuming and potentially erroneous data consolidation projects.
One of the most significant advantages of Greenplum within the Tanzu ecosystem is its ability to integrate data from a myriad of sources into a cohesive analytical environment. Whether it's structured data from traditional databases or unstructured data from IoT devices and social media, Greenplum provides the tools needed to consolidate, manage, and analyze data effectively. Its support for in-database analytics and machine learning algorithms allows data scientists and analysts to execute sophisticated workloads directly within the database, which accelerates time-to-insight and empowers organizations to leverage a more complete data set for faster, more informed decision-making.
Embracing real-time and unstructured data with Tanzu Data Services: Tanzu Data Services enabless organizations to harness the full potential of both real-time and unstructured data streams. With Tanzu Data Services, data engineers can seamlessly collect, process, and analyze data at the speed of business.
A key component of Tanzu Data Services is Tanzu RabbitMQ, a robust message broker that facilitates reliable, event-driven communication between different parts of an application. It excels in collecting and routing real-time data streams toensure that businesses can respond swiftly to changes, from adjusting inventory levels to analyzing social media sentiment.
Another vital element is Tanzu GemFire, an in-memory data grid that offers blazing fast data access that makes it indispensable for scenarios requiring quick data retrieval, such as real-time fraud detection or personalized recommendations. GemFire's ability to cache frequently accessed data or intermediate query results accelerates analytics and decision-making processes so that businesses can operate at speed.
VMware Tanzu's focus on interoperability brings seamless integration with your preferred database systems. Whether you’re leveraging the scale and analytical power of Tanzu PostgreSQL or the familiarity and compatibility of Tanzu for MySQL, your data collection and management infrastructure aligns with your organization's data strategy. This interoperability ensures that organizations can bring together real-time, streaming, and unstructured data sources for a comprehensive view of the data landscape, unlocking actionable insights that were previously out of reach.
Streamlining collection and integration with Tanzu Kubernetes Grid: Managing a complex data collection pipeline can become a bottleneck in itself. Data engineers need the ability to quickly spin up new data collection workloads, scale them on demand, and seamlessly integrate data from a multitude of sources without toiling with infrastructure resources. Tanzu Kubernetes Grid provides a flexible, container-based environment for deploying, scaling, and managing data collection and ingestion tasks. With Tanzu Kubernetes Grid, data engineers can easily deploy custom data collection workloads, connect to a wide array of data sources via APIs, and manage the entire data ingestion pipeline with the orchestration power of Kubernetes. This simplifies the process of bringing new data into the data science ecosystem, regardless of its origin or format, and streamlines data collection. By accelerating the data lifecycle, data science teams have timely access to the most up-to-date and diverse datasets for model building and analysis, which leads to more accurate and actionable insights.
By leveraging Tanzu solutions, organizations can overcome the challenges of disparate data sources, data growth, variety, governance, security, and compliance, and create a strong foundation for data science initiatives. Our integrated approach not only streamlines data management, it also accelerates the journey from data collection to actionable insights.
Now, let's see how MAST, a well-known name in the field of astronomical research, successfully addressed these challenges with a data science platform.
Revolutionizing astronomical discovery with Greenplum
The Barbara A. Mikulski Archive for Space Telescopes (MAST) is a vital resource for the astronomical community, serving as a repository for data from over 20 astronomical missions, both active and retired, including space and ground-based observatories. MAST is a cornerstone for the astronomical research community, enabling scientists to leverage historical and contemporary data for a wide range of research projects and scientific inquiries that, drive forward our understanding of the universe. Its primary function is to support and facilitate research in astronomy by providing access to a wealth of data.. By providing access to a comprehensive archive of astronomical data, MAST enables researchers to conduct studies ranging from the analysis of individual celestial objects to large-scale surveys of the universe.
Astronomical data, particularly from space telescopes like Hubble, James Webb, and the upcoming Nancy Grace Roman Space Telescope, can amount to several hundred billion rows of data for a single query. The sheer volume of data made it difficult, and time consuming, for researchers to process queries quickly and efficiently with existing database systems, which were not optimized for such large-scale data processing tasks. Researchers looking to analyze data beyond a certain scale had to manually segment queries and run them on multiple servers over several days. They then had to spend several days consolidating the results into the final data set, resulting in a fragmented approach was not only inefficient, but also placed unnecessary burdens on researchers and slowed down the pace of scientific discovery. The growing volume of astronomical data required a database solution that could scale dynamically and accommodate future data growth without compromising performance. Traditional database systems often struggled to provide the necessary scalability and flexibility MAST required, making it challenging to adapt to the increasing complexity and size of astronomical datasets.
Greenplum offered a solution capable of providing a scalable, distributed database that is optimized for large-scale data analytics. MAST deployed Greenplum on a robust 40-node cluster for fast, scalable analysis of massive astronomical datasets with improved query speed and a future-proofed platform. With Greenplum, MAST can process several hundred billion rows of data in only eight to 10 minutes, a task that previously took much longer and required manual data segmentation. Greenplum's distributed nature allows for faster query execution across large datasets, significantly reducing the time researchers spend waiting for query results. Greenplum's scalable infrastructure means that MAST can handle increasing volumes of data without encountering previous limitations, ensuring that the archive can continue to support astronomical research at an expanding scale.
Greenplum enables MAST to enhance its data processing and analysis capabilities, thereby supporting the astronomical community more effectively while fostering scientific discoveries by making vast datasets more accessible and manageable.
Solidifying foundations, paving future pathways
In this part of our data science platform journey, we've navigated the complexities of data collection and management, and how to transform raw, disparate data into a cohesive, actionable asset. This work is foundational, going beyond gathering data to creating a data-driven culture that propels innovation, efficiency, and competitive advantage.
Taming data sprawl can shorten project timelines, decrease response time, and proactively monitor your compliance posture. These are all critical victories for organizations fostering a data-driven operating model. As we conclude this exploration, we stand at a critical point: The transformation of data into a strategic resource that powers business growth and innovation.
VMware Tanzu empowers data engineers to be the architects of this success. With Tanzu, businesses establish a reliable foundation, seamlessly combining structured, unstructured and real-time data while prioritizing governance and security from the ground up.
From the management of vast data lakes with Tanzu Greenplum to the real-time processing capabilities of Tanzu Data Services, and the seamless integration offered by Tanzu Kubernetes Grid, VMWare Tanzu ensures that data is not just collected but effectively harnessed. This empowers confident analytics, transforming data from an unwieldy torrent into an asset yielding strategic insights.
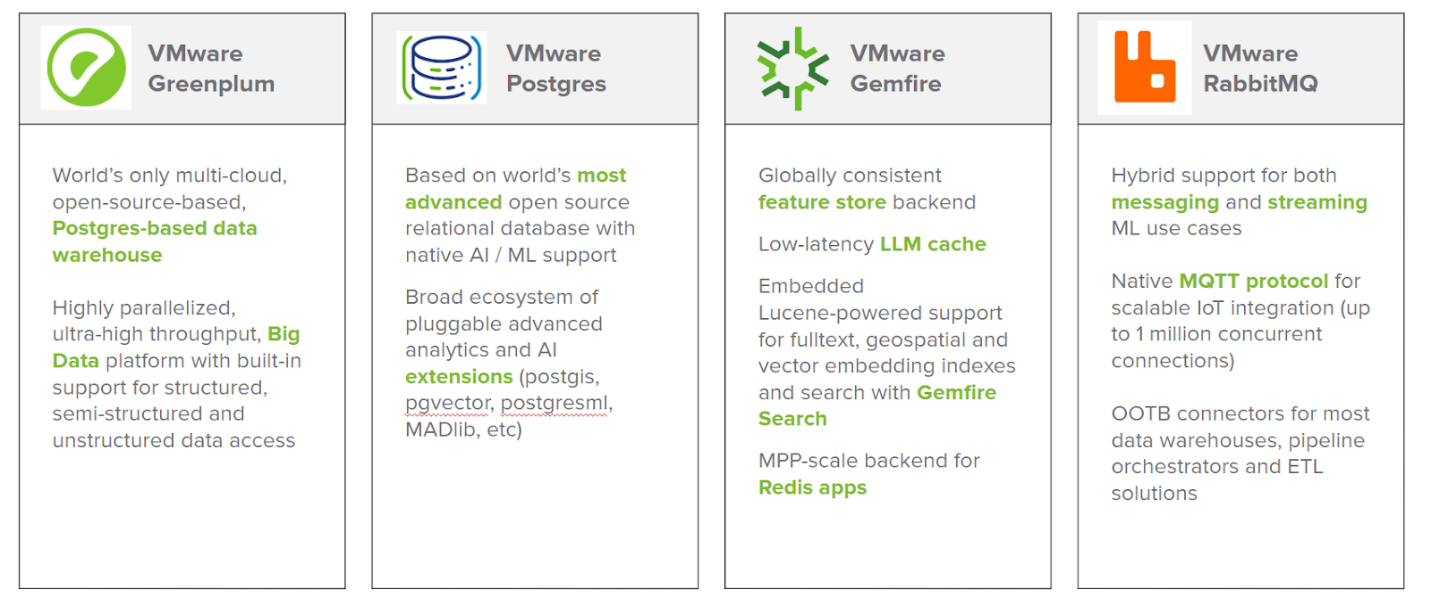
Fig 1.2: Foundational tooling for Data Collection & Management
The transition from data collection to actionable insights is where the true value of a data science platform is realized. With Tanzu, businesses can overcome the bottlenecks of data processing and management, setting a strong foundation for advanced analytics and model development. This foundation enables businesses to be agile, to respond to market shifts with data-driven decisions, and to maintain a proactive stance on compliance and security.
With robust data collection in place, the next hurdle awaits. Without careful preparation, even the most sophisticated models will stumble over inconsistent data, leading to skewed results and missed opportunities. Ready to streamline data transformation for insightful analytics? Join us as we explore the transformation of data into insights that drive action, powered by VMware Tanzu.
Read the other posts in the series, where we cover:
Part 1 - Data science platform revolution
Part 2 - Data collection and management
Part 3 - Data processing and transformation
Part 4 - Building innovative ML models
Part 5 - Deployment and operationalization of models (coming soon)
Part 6 - Monitoring and feedback (coming soon)
Part 7 - Principles and best practices (coming soon)
About the Author
Follow on Linkedin More Content by Pradeep Loganathan



















