

This is the first in a series of blogs that will provide you with a roadmap for building a data science platform using VMware Tanzu. We'll delve into the building blocks of a successful platform that drives data-driven insights.
Through this series, we'll dissect the architectural decisions, technological integrations, and strategic approaches that underpin successful data science platforms, and highlight how Tanzu can help. Whether you're architecting a new platform or optimizing an existing one, join us as we explore how to create data science environments that foster innovation, efficiency, and growth.
In this first blog, we'll uncover why a data science platform is essential to maximize your data's potential and explore its key components.
Data Science Platform: A crucible of innovation and collaboration
Imagine meticulously building a churn prediction model that’s been deemed essential to your company’s customer retention efforts, one that can save you millions of dollars by identifying customers at risk of leaving. Now imagine it’s left to languish in a spreadsheet, never reaching its potential to impact your business, not to mention the wasted resources and people power involved. This scenario, sadly, is not uncommon. A data science survey by Rexer Analytics reported that a staggering 87% of data science projects never reach production.
This statistic highlights only one of the challenges many organizations face when turning data science initiatives into real-world applications. One area particularly ripe for improvement is in the development of new machine learning models. While data scientists are great at building models, they don’t have the skills to integrate these models into real world applications that can predict outcomes or operationalize models. Data science platforms have emerged as a cornerstone when transforming theoretical potential into tangible business impact.
Data science platforms can accelerate innovation and collaboration across organizations and teams effectively and efficiently in several ways.
First, as a central hub, data science platforms unite the various components of the data science lifecycle within a streamlined and secure environment. It provides data scientists with efficient access to tools, libraries, and infrastructure, fueling experimentation and knowledge sharing to ensure compliance and keep projects on track. Data scientists can select their preferred tools, libraries, and programming languages, all while seamlessly integrating with the platform's broader data management and collaboration capabilities.
A data science platform also removes the burden of infrastructure setup and maintenance from individual data scientists. This allows data scientists to focus on their core expertise, whether that's specialized statistical modeling, deep learning techniques, or domain-specific data analysis. Streamlined workflows mean data scientists and engineers spend less time on logistics and more time on experimentation and model building, accelerating innovation cycles.
This means that collaboration is no longer ad-hoc and error-prone, but is built into the platform itself. Shared workspaces, standardized toolsets, and integrated versioning make it easier for teams to share insights and build on one another’s success. This collaboration isn't just about efficiency gains—it's about unlocking insights that no one person could have achieved alone.
Beyond streamlining individual workflows, a data science platform fosters a powerful collaborative dynamic. This unified environment ensures consistency in practices and outputs, and makes it easier for teams to leverage one another’s work. Integrated dashboards and reports bring visibility to stakeholders across the organization. These benefits aren't simply about improving team efficiency—they also create the foundation for truly data-driven innovation throughout an entire organization. From accelerating product development to optimizing internal processes, a data science platform lays the groundwork to unlock powerful insights that drive a competitive advantage—enhanced by specialized offerings from VMware Tanzu to support each stage of the process.
At its core, the data science platform embodies a sophisticated, multi-tiered architecture that forms the bedrock of data-driven intelligence. This infrastructure transcends a mere sequential flow of tasks, representing a dynamic synergy of technologies, expertise, and processes. Each layer within this architectural framework, as illustrated in Fig 1.1, is critical to fulfilling distinct function, and is steered by proficient individuals whose specialized skills are essential in transforming raw data into invaluable strategic resources. Let's dive into each of these layers.

Data Collection and Management: The arena of data engineers
At the foundational layer of this stack lies robust data collection and management, the bedrock of data science. Data engineers play a pivotal role here, orchestrating the architecture that collects, processes, and stores data. They manage the intricacies of data ingestion, storage, and processing, ensuring that data is not only high-quality and accessible, but also secure. For instance, integrating customer interaction data from diverse touchpoints—ranging from digital marketing platforms, legacy CRM systems, and social media interactions—presents a formidable challenge. Data engineers employ sophisticated data ingestion and management strategies to unify these streams, providing a holistic view of the customer journey. This integration is pivotal, transforming raw, unstructured data into a structured, queryable format that forms the foundation for actionable insights. Choosing the right technologies on which to build your platform is critical and should be considered carefully. With options spanning across relational databases, NoSQL databases, data lakes, and streaming platforms, data engineers can choose the best-suited foundation upon which the rest of their platform is built.
Data engineers not only ensure data quality and accessibility but also safeguard its security. With stringent regulations like General Data Protection Regulation (GDPR), California Consumer Privacy Act (CCPA), Personal Information Protection Law (PIPL), Personal Data Protection Act (PDPA) and others shaping data governance standards, data engineers implement robust access controls, encryption, and compliance measures. These safeguards maintain the integrity and confidentiality of data, fostering trust and enabling ethical data usage.
This layer transcends its role as a mere repository; it's a catalyst for complex analytical operations. A data science platform goes beyond simply storing data—it empowers transformation. Data engineers can manage a wide array of data types, from structured data to unstructured inputs like social media feeds and real-time sensor data, to complex semi-structured data such as logs and XML files. A data science platform can provide scalable storage and compute resources that adapt to changing data demands and policies, avoiding bottlenecks that slow down analysis and decision-making.
The massively parallel processing capabilities of VMWare Tanzu solutions, including Tanzu Greenplum, enable data engineers to analyze large datasets quickly and uncover insights that would remain hidden with traditional tools.
Data Processing and Transformation: Where data engineers and data scientists converge
Raw data is not actionable and analyzable. This layer of the platform is the refinery, transforming inconsistent data into insights that can drive business decisions. Data engineers and data scientists collaborate in this crucial stage, working together to clean, organize, and prepare data for analysis. In this layer, data processing and transformation claim the spotlight, and data engineers and data scientists collaborate on the meticulous task of cleansing, transforming, and normalizing data to make it analysis-ready. Data engineers, with their deep technical expertise in handling vast datasets, employ a suite of sophisticated ETL (Extract, Transform, Load) tools and data processing frameworks. These tools enable the efficient transformation of disparate data sources into a unified, coherent structure that data scientists can readily utilize.
Here is where data scientists bring their analytical prowess and domain knowledge to the table, guiding the transformation process to ensure that the resulting data structure aligns well with analytical objectives and model requirements. They work closely with data engineers to define the necessary data transformations, including normalization, feature engineering, and the handling of missing values. This close collaboration ensures that the processed data not only supports but enhances the predictive power of subsequent models. The goal is crystal clear: To sculpt data into a coherent structure, ensuring consistency and laying the groundwork for profound analysis.
In this crucial transformation phase, VMware Tanzu Data Services and compute solutions play a pivotal role in empowering data engineers and scientists to efficiently process and transform data. Tanzu's compute solutions, optimized for both batch and real-time data processing, offer the necessary computational power and flexibility to handle diverse data workloads with ease.
Advanced Analytics and Model Development: Where data scientists excel
In the arena of data analysis and model development, data scientists take center stage. They explore the processed data, using statistical methods and machine learning algorithms to uncover patterns and insights. Their work is instrumental to building predictive models that forecast trends and behaviors. This phase is marked by the application of sophisticated statistical methods and machine learning algorithms to uncover deep insights and predict future trends. Through exploratory data analysis, data scientists gain a comprehensive understanding of underlying patterns and trends within the data. This understanding guides the selection of the most effective statistical methods and algorithms for the task at hand. They rely on versatile environments for experimentation, leverage containerization technologies at scale, and take advantage of elastic computing platforms to manage the complexity of model development.
Data scientists develop models using techniques that range from classical regression and decision trees to complex neural networks and beyond. The development of predictive models, from simple techniques like linear regression to complex neural networks, is both an art and a science. Data scientists leverage a variety of machine learning techniques, fine-tuning parameters and employing validation strategies to ensure models not only fit the current data, but are also generalizable to new, unseen datasets. This iterative process, supported by collaboration tools, enables continuous refinement based on performance metrics and feedback, which ultimately leads to robust models that inform strategic decisions and innovation. Examples of this include predicting customer churn, recommending products for cross-sell, detecting anomalies, or optimizing business processes.
VMware Tanzu empowers data scientists to thrive in this environment by providing easy access to a curated library of leading data science tools, the latest frameworks, and streamlined workflows. Tanzu Platform empowers data scientists with a streamlined, cohesive environment for the rapid development and deployment of innovative machine learning models. With pre-built application accelerators, integrated CI/CD pipelines, and simplified deployment, data scientists can quickly put models in front of users and start gathering valuable feedback, fostering an agile, experiment-driven approach to model development that significantly accelerates the journey from idea to impact.
Deployment and Operationalization: Where DevOps meets data scientists
Deploying models transcends mere technical execution, and this stage is essential for achieving a true return on your data science investment. It involves transforming insights into actionable outcomes in a process where data scientists collaborate with DevOps and MLOps specialists to integrate models seamlessly into business systems. In the deployment and operationalization phase, integrating practices from DevOps and MLOps with the expertise from the field of data science becomes crucial for translating data-driven insights into actionable business strategies. This collaboration ensures that machine learning models are not only deployed into production environments but are also continuously refined, secured, and fine-tuned for efficiency, scalability, and adaptability.
This phase marks the culmination of the data science journey, where validated and optimized models transition from data science workspaces to real-world applications. Here, machine learning models become integrated into wider business operations. At the heart of this integration lies the challenge of embedding sophisticated models into dynamic business systems without losing the essence of their predictive power.
VMware Tanzu provides the technological backbone and collaborative environment necessary for these two worlds to converge, enabling organizations to unlock the full potential of data science endeavors. Technologies such as Tanzu Kubernetes Grid (TKG), along with specialized MLOps platforms (such as MLflow or Kubeflow), enable scalability and streamlined management of models in production. It streamlines model deployment, enables effortless scaling, and provides centralized management capabilities that optimize model performance in production.
Monitoring and Feedback: Completing the cycle
The culmination of the data science process hinges on effective monitoring and feedback mechanisms. This phase is critical to ensuring that deployed models deliver the intended outcomes and remain relevant over time. With a focus on automation, governance, and continuous monitoring, this phase helps guarantee that models perform reliably, ethically, and in accordance with business goals and regulations. Robust monitoring systems track both technical metrics and how the model's predictions impact key business KPIs. This feedback loop is essential to fostering a culture of continuous improvement, one where data-driven insights lead to iterative enhancements, and models are optimized for greater relevance and reliability. Data scientists can identify areas where the model needs refining, ensuring that it delivers maximum value over time.
Data scientists and business analysts track the performance of deployed models. They utilize metrics relevant to the model's purpose (drift, accuracy, precision, recall, etc.) as well as overall business impact. With meticulous monitoring, models remain accurate, relevant, and aligned with evolving business needs. Importantly, this feedback loop enables data scientists to make iterative improvements by refining models based on real-world performance.
Robust monitoring tools are essential for visualizing key metrics, tracking trends, and facilitating data-driven decision-making. By embedding monitoring and feedback deeply within the data science lifecycle, organizations can sustain a responsive and adaptable data science ecosystem. This ecosystem not only maximizes the value derived from data, it also empowers teams to navigate the complexities of an ever-changing data landscape with confidence and strategic foresight.
VMWare Tanzu Intelligence Services, with its broad spectrum of Application Performance, Hyperlogs and Observability combine with AI/ML based analysis to give you unparalleled insights into model performance metrics.
As we've explored the intricate layers of a data science platform, from data management to model monitoring, we've seen how each component plays a crucial role when transforming raw data into actionable insights. Now, let's take a look at how these layers work together in a typical model development workflow, as illustrated in the following image.
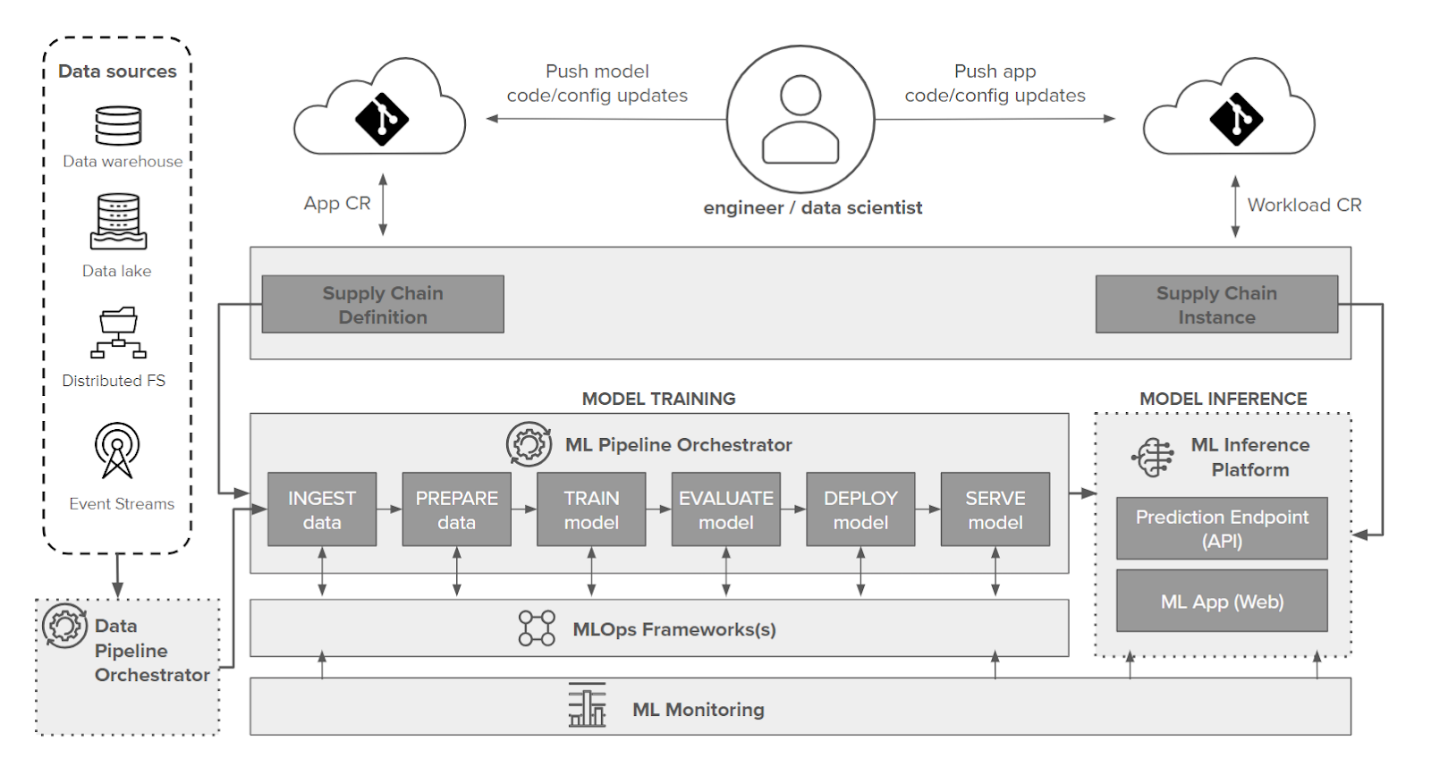
The journey from raw data to actionable insights requires more than just theoretical understanding. It’s here that Tanzu’s capabilities truly shine, offering an integrated, cohesive approach. Tanzu's suite of products are uniquely positioned to not only meet the diverse needs at every stage, but to also harmonize and enhance functionality across these layers.
Embracing the future with Tanzu for data science
In a rapidly evolving digital landscape, the role data science plays in driving innovation and creating competitive advantage has never been more critical. VMware Tanzu stands at the forefront of this revolution by offering a comprehensive suite of tools designed to address the unique challenges at each stage of the data science lifecycle. Although building a unified data science platform can be complex, Tanzu streamlines the process with a focus on integration, ease of use, and collaboration. VMware Tanzu supports each layer of the data science stack with a targeted approach, providing specialized tools and products that address the unique challenges and requirements of each layer. From robust data management to advanced analytics, deployment, and monitoring, VMware Tanzu's integrated portfolio ensures a seamless, efficient, and effective data science workflow.
In the world of data science platforms, VMware Tanzu emerges not just as a tool suite, but as a catalyst for innovation and collaboration. By leveraging Tanzu, businesses can harness the full potential of their data, optimize collaboration across diverse teams, and secure their position as leaders in the digital age.
This blog series is dedicated to unraveling the complexities of building and operationalizing data science platforms, offering a roadmap to turn theoretical potential into tangible business impacts.
Read the next blog in the series, Data Collection and Management, to learn about the data collection and management layer of the data science platform.
Read the other posts in the series, where we cover:
Part 1 - Data science platform revolution
Part 2 - Data collection and management
Part 3 - Data processing and transformation
Part 4 - Building innovative ML models
Part 5 - Deployment and operationalization of models (coming soon)
Part 6 - Monitoring and feedback (coming soon)
Part 7 - Principles and best practices (coming soon)
About the Author
Follow on Linkedin More Content by Pradeep Loganathan



















