

In my last post, I gave a short view of the recent history that drove the rapid rise of metrics adoption at companies such as Google, Twitter, Netflix, and others.
Here, I will explore fundamental differences between metrics and logs.
Metrics Format and Purpose
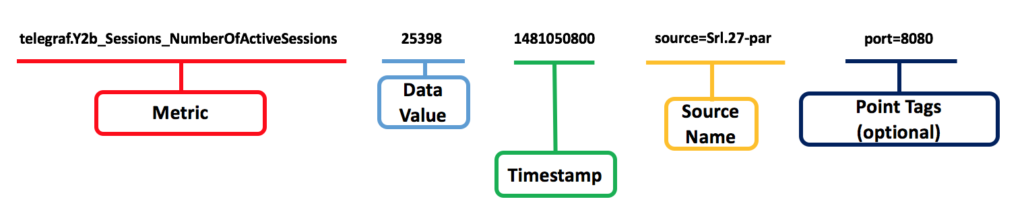
The purpose of a metric is to quantifiably assess the value of a desired variable over time. As such, the metric data format is short, and it describes your measurements beyond the measured value including type, location, the time of measurement, and grouping.
It includes metric name, value, timestamp, the metric source and an optional but a very useful point or source tag. Tagging helps you organize metrics by any aspect relevant to you; examples are port, host or container ID or many other aspects. Explore Wavefront docs for more details.
Metrics come from many different places including your custom or packaged applications, containers, infrastructure, cloud, business, other monitoring tools, IoT devices and many others.
There are many types of metrics you can collect, either standard ones such as OS performance or custom application or code metrics you define. Some commonly used metrics by development, SRE, and DevOps teams include:
- Application, code, or service performance and availability metrics: custom code error rate, application peak response times, transaction throughput, HTTP error rate, requests, etc.
- Infrastructure/cloud capacity and utilization metrics: CPU load, storage IOPS, memory, network throughput, virtual machine related metrics including (CPU ready time, memory balloon), container CPU or memory usage, etc.
- Business metrics: average shopping card spending on your website, $ per API hit, the rate of customer clicks per second, etc.
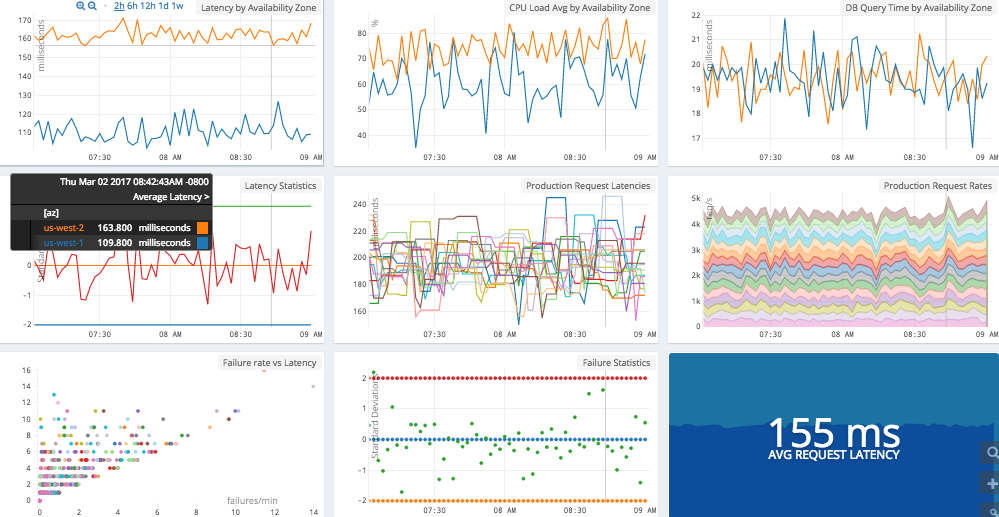
Due to their lightweight structure and numeric nature, metrics lend themselves to many mathematical transformations including aggregation, correlations, distributions/histograms, and many others.
Once the metrics are analyzed with Wavefront, DevOps teams (TechOps, SREs, developers, CloudOps, etc.) can manipulate the data streams at very high speed and perform iterative investigation across many unified views. Wavefront customers can ingest, analyze and visualize instantly millions of metric points per second.
As you adopt containers and microservices, expect the complexity of your code to grow. As well, your need for instrumentation and metrics will grow quickly too. It’s not uncommon to have thousands of distinct metrics coming from all corners of your distributed applications and cloud infrastructure.
But the beauty of metrics is its simplicity – as metric volumes grow, there’s negligible impact on the speed of visualization, processing, or storage. Moreover, at Wavefront, we don’t discard or roll-up any customers’ historical metrics. So all the detail you need to do “back-in-time” analysis for trending and anomaly detection is 100% available.
Now let’s touch on the format and purpose for logs.
Logs Format and Purpose
Logs can be described as lists of events that have occurred, so, therefore, they can come in a vast variety of shapes or forms. They can be single-line or multi-line such as call detail records. The purpose of a log event is to convey the information about a particular action such as user login, or a critical incident such as a disk failure.
Log records are typically generated by your infrastructure or your applications. Logs are used to provide various operational teams as much specific detail as possible to help them analyze a particular operational or security incident.
As a result, the log data format tends can be longer. Logs are typically used for navigating down to the root cause after something happened, for this reason, they are valuable when performing forensic analysis.
Some logs are standardized; but often, their formats are at the freedom of developers to define them. The below is an example of a short list of log events gathered from a Linux host.
Jun 17 09:47:21 pe-puppet-enterprise-release-3.7.2.0-1.pe.el5.noarch: 100
Jun 17 09:47:22 Installed: pe-openssl-1.0.0q-1.pe.el5.i386
Jun 17 09:47:23 Installed: pe-libldap-2.4.39-5.pe.el5.i386
Jun 17 09:47:23 Installed: pe-virt-what-1.13-1.el5.i386
To sum up the comparison, think of logs as lists of discrete events, packaged and optimized for deep, drill-down analysis, while metrics are packaged to facilitate a continuous view of your environment (and how it’s changing overtime), and optimized for aggregate, numerical analysis.
Getting the Most from Metrics, from Logs
Now that we introduced their differences, both metrics and logs are essential to understanding and improving the performance of your code, services, and infrastructure environment in production.
But usually, metrics and logs serve different purposes, and to get the operational insights you need to accelerate your application delivery at higher-scale, using purpose-built platforms for each type of analysis may be the most efficient for overall cost. In my next blog, I will help you explore these differences further as well as how to make the best use of them.
Watch the “To Log or to Metric” Recorded Webinar
If the metrics vs. logs topic is of interest to you, you may watch the recorded webinar, and see a demo and explore the metrics vs. logs dilemma with real-world use cases.
Get Started with Wavefront Follow @stela_udo Follow @WavefrontHQ
The post Metrics vs Logs Dilemma: Basic Differences (Part 2 of 3) appeared first on Wavefront by VMware.
About the Author
Follow on Twitter Follow on Linkedin More Content by Stela Udovicic





















